Confluent Cluster Linkingの仕組みについて
クラスタ間のレプリケーション - 一般的なアプローチ
クラスタ間でデータのレプリケーションのニーズは古くからあり、DRや組織内のグループ会社間/事業部間の部分的なデータ共有、またはUberさんのActive-Active双方向レプリケーションの様な使い方もあります。いずれにせよ、何かしらの形でKafkaクラスタから他のクラスタにデータをレプリケートするという手法は変わらず、また利用できるツールも (多少の機能差異はありながらも) 基本的に同じアプローチを取っています。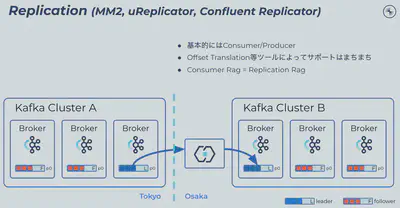
基本的なアプローチはどのレプリケーションツールでも同じで、Producer/Consumerの両方を司るKafka Connectコネクタとして稼働します。SourceクラスタのTopicからConsumeし、DestinationクラスタのTopicにProduceする、理解し易いアプローチだと思います。当然SourceとDestinationのTopicは別々のものなのでPartition数を変える事も出来ますし、一般的なコネクタ同様SMTを利用する事も出来ます。
同時に、Kafkaクラスタの外で双方にアクセス出来るコンポーネントを別途運用する必要性もあります。レプリケーションツールとKafkaブローカー間にはペイロードの圧縮/解凍処理を挟み、独立したConsume/Produce処理となる為レイテンシも比較的高くなります。またKafkaクラスタ同士がお互いを認識している訳ではなく、それぞれのクラスタに存在するTopic同士も機械的な関連性はありません。当然双方のTopicのConsumer Offsetは全く独立して管理されている為、TopicにアクセスするConsumerをクラスタを跨いで移動させる場合には、何かしらの方法でConsumer Offsetを変換する必要性も発生します。
Cluser Linking - クラスタを跨いだReplica Fetching
Confluent Cluster Linkingのアプローチは大きく異なります。結果としてConsumer Offsetを含め全てのTopicに関するメタデータを完全に同期した状態でデータのレプリケーションが可能です。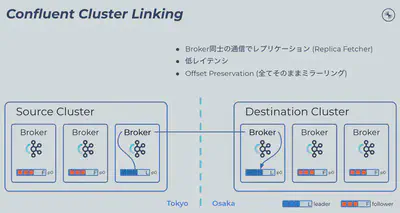
仕組みとしては、同一クラスタ内におけるKafkaのレプリケーションの仕組みに近く、Replica Fetcherと近い形でDestinationクラスタにあるBrokerがクラスタ境界を跨いでフェッチする形でレプリケーションを行います。処理を仲介するものも、ワークロードの何かしらの受け渡しの様な処理も無いため、スループットも高く、また低レイテンシなレプリケーションが可能です。
当然仲介用のConnectクラスタ等別途立ち上げる必要はありません。リンクの設置も、SourceもしくはDestinationクラスタであるConfluent CloudもしくはPlatformに対してリンク作成コマンドを実行すれば完了します。
特徴と注意点
先にメリットについては記載しましたが、非同期レプリケーションではありながらSourceとDestinationのデータ差 (オフセット) がこれまでのアプローチよりかなり小さく、また安定的に同期出来るので、DR等の適用時において復旧/欠損対象となるデータ量を限定する事が出来ます。メタデータごと完全に同期しているのでクラスタ間のデータギャップやその復旧時の運用負荷も下がります。フェイルオーバーを考えると、Cluster Linkingを利用した場合にはオペレーションをかなり簡素化出来るのが特徴です。
注意点 1 - 障害時にデータの欠損は起こり得る
Cluster LinkingはMirrorMaker2等と比べると、確かに低レイテンシでデータの同期が可能です。しかしながらあくまで同期ではなく非同期のレプリケーションである為、RPO (Recovery Point Objective: 目標復旧地点) は0ではありません。Sourceクラスタにおいて、「書き込み完了と判断された後」かつ「その変更がDestinationクラスタ側からフェッチされるまで」にSourceクラスタがダウンしてしまう可能性はあり、この条件に合致する差分はSourceが再度復旧出来るまでアクセス出来ません。
注意点 2 - TopicはPartition数を含め完全一致
DestinationクラスタにレプリケートされたTopicはMirror Topicと呼ばれる少し特殊なTopicです。具体的には:
- 全Partitionのイベント数、イベント順序、各イベントのデータが全てSource Topicと全く同じとなる。
- Read OnlyでありDestinationクラスタ内から書き込み不可。1 となります。
この為、例えばSourceクラスタのTopicからSMTを使って特定フィールドをマスキングしたり、Sourceと異なるPartition数をDestinationで指定する事は出来ません。
注意点 3 - フェイルオーバー後の復旧はフェイルフォワードを推奨
Cluster LinkingではDR時にフェイルオーバーした際、基本的にDRであったクラスタを今度は本番と位置付けるようコマンドが整備されています。例えば東京リージョン (Prod) から大阪リージョン (DR) へのフェイルオーバー時に、大阪が本番リージョンとして機能します。その後東京リージョンが復旧した場合、フェイルバックするのではなく今度は東京をDRとして継続オペレーションを実施することを推奨しています。
おわりに
上記に注意点を幾つか並べましたが、どれもCluster Linkingの欠点と言うよりは特性であり、つまりこの特性を充分理解した上でレプリケーション戦略を立てる事が大事です。
- 注意点 1 - これは非同期レプリケーションである限り避けようがありません。逆に、非同期なのでSourceクラスタに対する書き込みレイテンシには影響を与えないメリットもあります。
- 注意点 2 - 通常のReplica Fetcherの仕組みと近いと考えると当然で、バイトレベルで同一のデータをDestinationクラスタ上に持てるというメリットを考えると納得出来る制約だと思います。
- 注意点 3 - これは意見が分かれるところかも知れません。データ基盤全体におけるBC戦略はKafkaのみのルールで決めれるものでは無いので、許容出来ないユースケースは多いと思います。ただ作業の手間が増えるだけで、フェイルバックする事は不可能ではありません。
他にも場合によってはMirrorMaker2やConfluent Replicatorの方が理に適った選択肢であるケースはあり、実際にもCluster LinkingではなくConfluent Replicatorを採用されるユーザーもいます。確かにCluster Linkingは画期的なレプリケーション機能ではありますが、その特性を理解した上で採用を判断する事が (何事に言える事ですが) 重要です。
当然DR時にはMirror Topicを元にオペレーションを再開するので、その際は
kafka-mirrors --failoverコマンドで書き込み出来るよう切り替えます。 ↩︎