解剖 Kafka Controller Broker

このブログエントリはKafkaコミッタである Stanislav Kozlovski(𝕏|Ln) のサイトで2018/10/31に公開されたApache Kafka’s Distributed System Firefighter — The Controller Brokerの日本語訳です。Stanislav本人の了承を得て翻訳/公開しています。
はじめに
Kafkaは成長を続ける分散ストリーミング基盤です。現時点での業界デファクト技術であり、広がるデータパイプラインの利用に対しても拡張しつつ安定的に稼働することが出来ます。もしKafkaの概要についてもう少し知りたい方はA Thorough Introduction To Apache Kafkaをご覧ください。
この記事を書く中で、このKafkaの安定稼働を支える中の仕組みについて書きたいと思うようになりました。
このエントリではKafkaにおけるControllerの概念 - Kafkaという分散基盤を健康的に稼働し続ける使命を支える機能についてご紹介します。
Controller Broker
分散システムは常に協調の中で稼働し続ける必要があります。何かしらのイベントがクラスタで発生した場合、クラスタ内のコンポーネントは同調してそれに反応しなければいけません。その中で、クラスタとしてどう反応するべきなのか、Brokerは何をすべきなのかを指示する存在が必要です。
その役割を担うのがControllerです。 Controller自身は複雑な仕組みではありません - ControllerもBrokerであり、通常のBrokerとしての役割と合わせて追加の役割も持つBrokerです。つまりController BrokerもPartitionを制御し、ReadとWriteのリクエストに対応し、裏ではレプリケーションに参加します。
今追加の役割の中で最も重要なのは、クラスタ内のBrokerノードの管理であり、Brokerが追加、クラスタから離脱、もしくは障害が発生した際に適切にそのメンバーシップを管理することです。これにはPartitionのリバランスや新たなPartion Leaderの特定も含まれます。
KafkaクラスタにはControllerが常に稼働し、唯一1つのControllerのみ稼働します。1
Controllerの役割
Controller Brokerは複数の複数を担います。Topicの作成/削除、Partitionの追加 (とLeaderの特定)、BrokerがClusterを離脱した際の諸々の制御等様々ありますが、基本的にはクラスタにおける管理者として振る舞います。
Brokerノードの離脱
エラーや計画的な停止によってBrokerノードがクラスタから離脱した際、そのBrokerノードにLeaderのあったPartitionにはアクセス出来なくなります。 (クライアントはWrite/Readのいずれであっても常にPartition Leaderにのみアクセスします。2) この為Broker離脱時のダウンタイムを短縮するには、いかに迅速に新たなLeaderを選出するかが重要になります。
Controller Brokerは他のBrokerノードが離脱した際に対処します。ZookeeperにはZookeeper Watchと呼ばれる特定データの変更時に登録者に対して通知をする機能で、ControllerはこのZookeeper Watchを利用してBrokerの離脱を検知します。Zookeeper WatchはBroker離脱時のトリガーとして働くKafkaにとって非常に重要な機能です。
ここにおける「特定データ」とはBrokerデータの集合です。
下にあるのはBroker 2のZookeeper Sessionが無効化される事によりBroker 2のIDがリストから削除された場合の図解です。(Kafka BrokerはZookeeperへのハートビートを送り続けるが、遅れなくなるとセッションが無効化する)
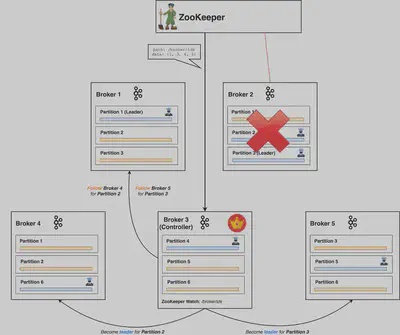
ControllerはこのBroker離脱の通知を受け取り作業に取り掛かりますが、まずはBrokerの離脱によって影響を受けたPartitionの新たなLeaderを決定します。この後、クラスタ内の全てのBrokerに対して通知し、このリクエストを受け取った各Partition毎にLeaderになったりFollowerとしてLeaderにLeaderAndIsrリクエストを送付します。
Brokerノードのクラスタ復帰
適切なPartition Leaderの配置はKafkaクラスタの負荷分散の上で重要な要素です。上記で説明したとおり、Brokerノードがクラスタを離脱した際には他のBrokerが代わって対応する必要があります。この場合Brokerは当初の想定以上のPartitionを各々が担うことになり、クラスタ全体の健全性やパフォーマンスに少なからず影響を及ぼします。当然なるべく早くバランスを取り戻す必要があります。
Kafkaは元々のPartitionアサインメントが、ある程度「適切」であるという想定を持っています。このアサインメントにおけるPartition Leaderはいわゆる Preferreed Leader(優先リーダー) として認識され、最初にそのPartitionが追加された時のPartition Leaderを指します。合わせてKafkaはインフラ構成としてのラックやAvailability Zoneを意識したPartition配置の機能 (ラック/AZ障害耐性を確保する為にLeaderとFollowerを別のラック/AZに配置する) もサポートしており、Partition Leaderの配置はクラスタの信頼性に大きく寄与しています。
デフォルトではauto.leader.rebalance.enabled=trueとなっており、KafkaはPreferred Leaderが存在し、かつ実際のPartition Leaderではない場合にはPreferred Leaderを再選出します。
Brokerノードのクラスタからの離脱も、多くの場合一時的であり、ある一定時間経過後に離脱したBrokerノードは再度クラスタメンバーとして復帰します。この為Brokerノードが離脱した際にも関連するメタデータは即座に削除されず、Follower Partitionも新たにアサインされません。
注意点として、再参加したBrokerノードも直ぐにPartition Leaderとして再選出される訳ではなく、その候補となる為には別の条件も必要となります。
In-Sync Replicas
In-Sync Replica (ISR) は状態がPartition Leaderと同じ Followerを指します。言い方を変えると、ISRはそのLeaderのレプリケーションが追いついている状態にあります。Partion LeaderはどのFollowerがISRでどのFollowerがそうではないかをトラックする必要があり、その状態はZookeeperに永続化されます。
Kafkaの障害耐性と可用性の保証はデータのレプリケーションに基づいており、kafkaが機能するには常に十分なISRが確保されているかが極めて重要です。
FollowerがLeaderに昇格するにはまずISRである必要があります。全てのPartitionにはISRのリストがあり、Partition LeaderとControllerによって管理されています。ISRから新たなPartition Leaderを選出する処理は Clean Leader Election と呼ばれています。一方ユーザーにはこれとは異なる方法でLeaderを昇格させる事も可能で、Partion Leaderがクラスタを離脱した際にはISRではないFollowerを昇格させる事も可能です。これはLeaderもISRも存在しないという状況において、データ整合性より可用性を優先させる必要がある稀なケースです。
ここで再度の確認になりますが、クライアントはPartition LeaderからしかConsumeできません。仮にISRではないFollowerをLeaderに昇格した場合には、当然まだLeaderから取得されていなかったメッセージは失うことになります。これはメッセージを失うだけでなく、Consumerから見たイベントのストリーム上の位置 (オフセット) も上書かれます。
残念ながらClearn Leader Electionの場合にも同様のデータ障害が発生する可能性はあります。ISRも様々な要因によってLeaderと完全に同期が取れていないケースです - 具体的には、Leaderのオフセットが100とした時に、Followerのオフセットが95、99、80となっているような状況です。レプリケーションは非同期に実施される為、最後のメッセージまで完全にFollower側に渡ったと保証する事は困難です。
FollowerがLeaderに対してin-syncであると判断する条件は以下です:
- Partition Leaderから最新のメッセージを X ミリ秒前に取得している。 (Xは
replica.lag.time.max.msにて設定可能) - Zookeeperに対して Y ミリ秒前にハートビートを送っている。 (Yは
zookeeper.session.timeout.msにて設定可能)
データ整合性と耐久性
Leaderが機能不全に陥った場合、状況によってはISRが新しいLeaderに昇格した場合にも僅かにメッセージを失う可能性がある点について言及しました。具体的にはLeaderがFollowerからのフェッチリクエストを処理し終わった直後に新たにメッセージを受け取ったケースで、この場合新たなメッセージはまだFollowerがメッセージの到着を把握するまでの空白期間が存在し得ます。このタイミングでLeaderが機能不全に陥った場合、メッセージはLeaderにしか存在しないながらもFollowerの一部はISRとして成立します。そしてISRがそのままLeaderに昇格する可能性があります。
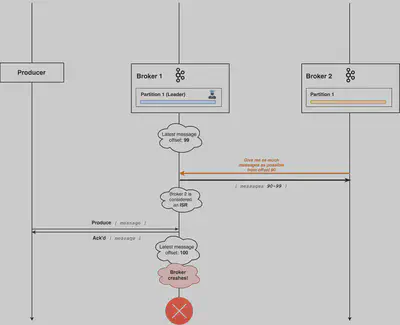
Produer側のAcksの設定
上記の例ではLeaderは自身への書き込みが完了した時点でAcksを返す設定 (acks=1) を想定しています。Broker 1が最後のAcksを返した直後に機能不全となった為、Broker 2はISRではあるもののoffset:100のメッセージは受け取っていない状態でLeaderに昇格しています。
この事象はacks=allと設定することにより回避する事は可能で、つまりLeaderは全てのISRへの書き込みが正常終了した時点で初めてacksを返します。残念ながらこの設定の場合クラスタ全体のスループットには影響します。Kafkaのレプリケーションはpullモデルである為、Leaderは全てのISRのフェッチリクエストが届き、またそれが完了するまで待たなければいけません。
いくつかのユースケースでは、パフォーマンスを優先してacks=1とする場合もあります。
acks=allと設定した場合にメッセージの欠損は回避出来ます。新たにLeaderとなったISRには無いメッセージを既に取得したConsumerが出る可能性もありません。Producerからのacksを元にデータの整合性は保たれます。
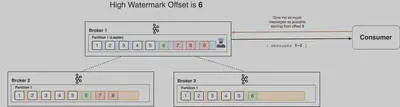
High Watermark Offset
Leaderは全てのISRへのレプリケーションが完了しない限りacksを返さないとします。この際Brokerは high watermark offset と呼ばれる「全てのISRが取得済みの最大のオフセット」を管理しています。Leaderは合わせてConsumerからのリクエストに対してこのhigh watermark offsetを超えないメッセージのみ提供する事により、DBで言うところのNon-Repeatable Readを回避しています。
Split Brain
Controller Brokerがダウンした場合、メタデータの欠損を回避する為にKafkaは急遽代理のControllerを立てる必要があります。
ここでの問題は、我々にはController Brokerの応答不能が完全な機能不全によるものなのか、それとも一時的な障害 によるものかの判断が出来ない事です。それでも新たなControllerを選出する必要がありますが、場合によってはZombie Controllerを生み出す危険性もあります。つまり、クラスタからは既に稼働を停止しControllerではないと認識されているにも関わらず、再びアクティブとなりControllerとして振る舞うBrokerです。
この事象は容易に起こり得ます。例えば一時的なネットワークの分断が発生した場合や、非常に長いGC Pause(Stop-the-World - 全ての処理がGCの実行完了まで停止される事象)が発生した場合には、ClusterはそのController Brokerが既に停止したと判断し得ます。特にGC Pauseの場合、Controller Brokerの観点では何一つ変わっていないのに時間が経過している状況となります。この為、Controllerが既に選出された後に以前のControllerが復帰する、分散システムにおけるSplit Brainが発生します。
例に準えて解説します。稼働中のControllerが長いGC Pauseに陥ったとします。ControllerのZookeeper Sessionが無効化され、/controllerznodeは削除されます。クラスタ内の他のBrokerは通知を受けます。
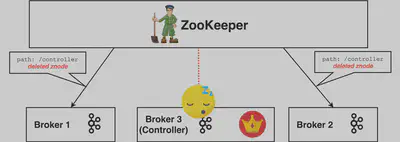
Controllerの不在状況を回避する為、全てのBrokerがControllerになろうとします。この場合Broker 2が選出され新たなControllerとして/controllerznodeに自身が追加されます。
全てのBrokerはこの新たなznodeが作成され、Broker 2がControllerである通知を受けます。この際にも唯一GC Pause中のBroker 3だけはこの通知を受けません。ちなみにこの通知がBrokerに到達しない可能性は他にもあります。いずれにせよ最終的にBroker 3には新たなController選出の通知が届きません。
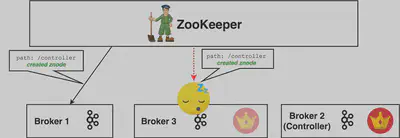
Broker 3でのGC処理が完了し復帰した際、未だに自身がControllerだと認識しています。

結果として2つのControllerが稼働状態となり、異なる指示を並行して送る可能性があります。この状態はクラスタの状態として極めて悪く、適切に対応しなければ重大なデータ不整合を起こし得ます。
もしBroker 2(新たに選出されたController)がBroker 3から指示を受けた場合、このBroker 3が新たなControllerであるという保証は取れるのでしょうか?もちろんBroker 2も同様にGC Pauseに陥った可能性もあり、自分自身も最新のControllerではない可能性も否定出来ません。
何かしらの方法で、どのControllerが最新であり現在稼働すべきControllerであるのかを全員が判断出来る方法が必要です。
その方法は極めて単純に、epoch number3の利用により解決しています。epoch numberは単純に1ずつ増加する自然数であり、古いControllerのepoch numberが1の場合、新たに選出されたControllerのepoch numberは2になります。Brokerは単純に、最も大きなepoch numberを持つControllerからの指示を信じる事によりsplit brainを回避出来ます。このepoch numberはZookeeperに保全されます。(ZookeeperのConsistency Guaranteeの機能を利用しています。)
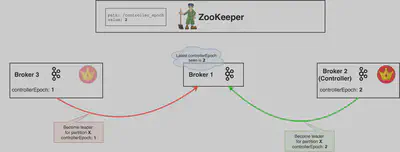
Broker 1が最も大きいcontrollerEpochをZookeeperに保全する事になり、その他全てのより小さなepoch numberを持つControllerからの指示は無視されます。
その他の役割
Controllerには他にもやや地味な役割を担います:
- 新しいTopicの作成
- 新しいPartitionの作成
- Topicの削除
これら処理は、以前にはやや乱暴な方法で4処理されていましたが、version 0.11と1.0からはControllerへのリクエストにて処理する方法にと変更されています。この方法はAdmin Client APIとして提供され、Kafkaクラスタへアクセスするアプリや管理者にも容易にアクセスすることが出来ます。
