Tiered Storageは何故そんなに重要なのか?
Tiered Storageとは
今年の後半にリリースが予定されているApache Kafka 3.6には、Tiered Storageと呼ばれるKafkaコミュニティが待ち望んだ新機能が含まれる予定です。この機能はKIP-405として何年も前に登録されたKIPであり、長い期間をかけてようやくリリース目処が経ちました。
これまでKafkaのデータは常にBrokerのストレージに格納されていましたが、これを二層化して古いセグメントを自動的に退避するという機能です。Kafkaに格納されたイベントをオブジェクトストレージに退避するというプラクティスは一般的であり、これまではKafka Connectコネクタを使って自分で退避させるアプローチを取っていました。これをKafkaネイティブな機能として提供する、その役割をKafka Brokerが行うというものです。クライアントからはこのオペレーションは隠蔽化されており、新しいイベントも古いイベントも同じアプローチでアクセスする事が出来ます。
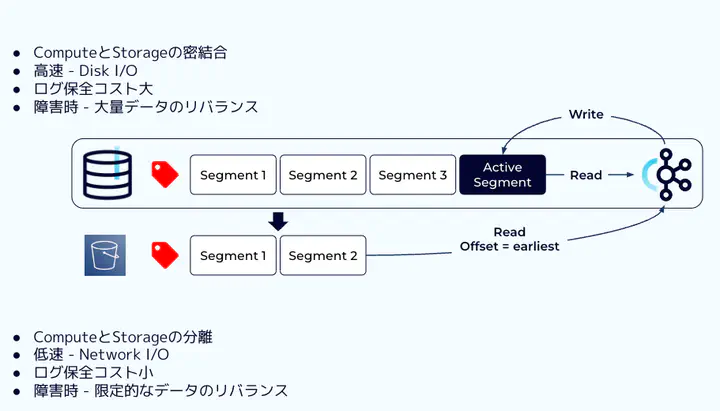
Tiered Storageの動き - 図解
これまで通り、クライアントから送られたイベントはkafka Brokerのストレージにセグメント単位で保存されます。セグメントはログファイルであり、ランダムアクセスではなくアペンドでしかデータを足せない為、最も新しいセグメント (Active Segmentと呼ばれます) 以外のファイルは不可変 (Immutable) です。
Tiered Storageはこのうち古いセグメントを自動的にオブジェクトストレージに退避します。
中では新しくRemoteLogManagerと呼ばれるプロセスが、これまでのLogManagerに近い役割を果たしつつリモートストレージにコピーし、合わせてリモートストレージのインデックス状態のキャッシュを保持します。
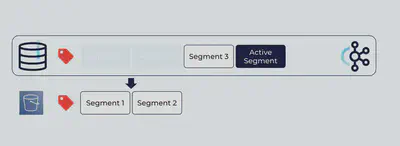
上にあるように、Broker側の保全期間 (Retention Period) を超過しセグメントが削除された後も、リモートストレージにはそのコピーが残ります。ストレージの動きはこれだけで、リモートからローカルにセグメントが戻ってくる様な事はありません。これまでのLog Managerの役割もそのままで、ローカルのログは今まで通り管理されます。
ほとんどのユースケースでは、クライアントは最新のセグメントに集中してアクセスします。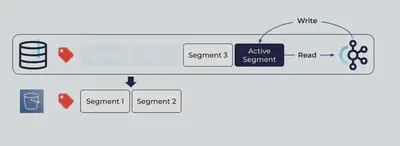
違いは、クライアントが古いセグメントにあるオフセットを指定して読み込みをリクエストした場合です。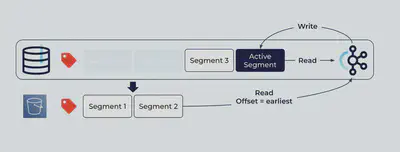
既にBrokerのローカルストレージにはセグメントは存在しませんが、リモートストレージに存在する限りBrokerはデータを取得しクライアントに返すことが出来ます。
メリット 1 - 拡張性 (Scalability)
Kafkaは拡張性に極めて優れたストリーミングプラットフォームであり、原則Brokerノードを追加することにより水平スケールする事ができます。一方、拡張には限界があります。一般的に大規模Kafkaクラスタにおけるボトルネックはネットワーク帯域で、次にストレージと言われています。これらを充分確保出来続ける限りKafkaクラスタは相当規模まで拡張出来ます。Tiered Storageによってストレージ容量の削減とより高度なコントロールが可能になります。
KafkaにとってそれぞれのTopicの保全期間 (Retention Period) と書き込みスループットは基本的にはバランスゲームです - 高書き込みスループットの場合はストレージ容量の増加を加味してより短い保全期間を指定する必要があります。保全期間のデフォルトでは1週間、通常運用では1日という場合も多くありますが、高負荷のクラスタでは数時間程度に留める事も多くあります。
kafkaは内部でデータのレプリケーションを行なっています。Replication Factorと呼ばれるこの設定のデフォルトは3であり、稀に金融やストレッチクラスタ (複数のサイトに跨がる大きなクラスタ) では4を指定する場合もありますが、ほとんどデフォルトのままではないかと思います。いずれにせよ、その指定分だけデータはレプリケートされるので、必要ディスク容量は増えます。
例えば100MBpsで書き込みがなされる場合、レプリケーションも考慮するとクラスタ内のネットワーク帯域には300MBps、当然ストレージにも300MBpsのスピードで消費します。保全期間を1日とした場合、100 * 3600 * 3 = 1,080,000MB ≒ 1TBのストレージ容量が必要となります。書き込みスループットが倍になればストレージも倍、当然保全期間を倍にしてもストレージは倍必要になります。
ストレージがボトルネックになった場合、ディスクを足せば解消しますが、それも限界を超えるとBroker自体を追加する必要が出てきます。Tiered Storageを導入すると、Brokerが必要とするストレージの絶対量を制限できます。同一ハード構成におけるキャパシティを上げ、将来的な拡張性も高く出来ます。
メリット 2 - 障害耐性 (Resiliency)
ストレージを分離する事によって障害耐性が上がるというのはピンと来ないかも知れませんが、Tiered Stoargeによる効果と期待は障害耐性の向上にも集まっています。
Kafkaが何事もなく稼働している限り、またデータが適切にパーティションされている限り、Kafkaクラスタは均一にデータを分散配置し管理出来ます。しかしBrokerのシャットダウンと復帰は必ず発生します。時としてハードやソフトの障害によって、他ではBroker/JVM/Guest OS/Host OS/Host Hardwareのアップグレードによって、クラスタ構成は短期/長期的にその構成が変わります - Kafkaは絶えずメンバーシップを変えつつ稼働し続ける分散システムであり、構成が変わる前提の上で成立している技術です。
Brokerがクラスタメンバーから外れると、それまでそのBrokerで保全していたデータは必ず何かしらの方法で他のBrokerに再配置されなければデータの保全性が保てません。この為クラスタメンバーシップの変更は、大規模なメタデータの更新と、データの移動を意味します。
Tiered Storageによって管理/移動対象となるセグメントの物理的な数が減れば、その分クラスタ内で移動するデータ量が減少し、また大量メタデータ更新に伴う二次災害の危険性も減少し、結果としてより安全に、より短い期間にクラスタが正常状態に復帰します。Kafkaクラスタ自体が軽量になればなるだけ、例えばコンテナの様により頻繁に刷新されるランタイム上でKafkaを運用する場合にも大きなメリットとなります。
メリット 3 - リソースの有効活用 (Resource Utilization)
Kafkaとは基本的にディスクI/Oへの負荷が高いプラットフォームです。これは書き込み/読み込みの発生頻度が高く、またディスクI/Oの有効利用が今回の設計思想に織り込まれています。併せて、Kafkaは原則マルチテナントプラットフォームであり、様々なワークロードが共存し易い (各々のワークロードの影響を受けにくい) ストリーミング基盤です。しかしながらKafkaにも物理的な制約は存在し、ワークロードのニーズ的にはクラスタ自体を分ける事も実際には多くあります。1
Tiered Storageへのアクセスは、Kafkaでは珍しくディスクI/OではなくネットワークI/Oへの比重が高い処理となります。例えば長期間実行するバッチ処理 (古いデータなのでTiered Storage経由) と、超低レイテンシな処理が求められるオンライン処理 (新しいデータなのでBrokerから) とではKafkaかかるリソース負荷が全く異なります。これら特性を上手く利用すれば、オンライン処理を実行しながら低負荷でバッチ処理を同一クラスタ内で扱う事も出来ます。2
おわりに
Tiered StorageはApache Pulserの様なコンピュートとストレージを完全に切り離す目的で導入される訳ではありません。Kafkaはある意味意図的に原始的な設計をしている点が長所であり、時として短所となり得る技術です。Tiered StoargeはKafkaが本来持つ高スループットかつ低遅延な処理能力を殺す事なく、短所であるディスク容量やディスクI/Oというボトルネックを軽減させ得る可能性を持った非常に有望な機能です。併せて、よりクラウドネイティブな環境で動く機会の増えたKafkaにとって、その新しい環境により適合性の高い機能であるとも言えます。