Queues for Kafkaとは何か?
そもそもメッセージキューでは無かったKafkaがどう変わろうとしているのか
はじめに
Apache Kafka® はメッセージキューと比較される事も多く、またメッセージキューとして利用される事も多くあります。KIP-932 Queues for Kafka はそのKafkaに対してネイティブにメッセージキューとして利用する機能性を追加するKIPです。
Consumer Group
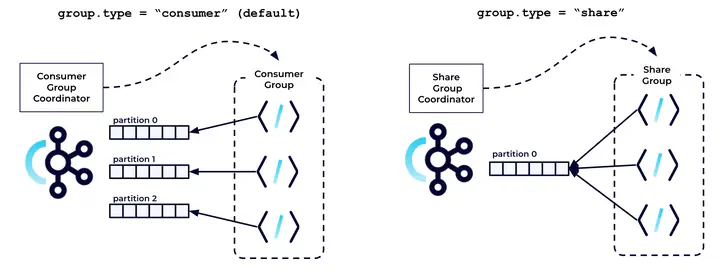
Kafkaは仕組み的にはメッセージキューではない、と言うのは語弊があるかも知れません。もう少し正確に説明すると「メッセージの順序保証 (Order Guarantee) を確保する為にスケールする際に制限がある」仕組みを採用しています。この仕組みはConsumer Groupと呼ばれ、Kafkaにおけるデータの分離単位であるPartition単位にメッセージの順序保証をするアプローチです。
Consumer Groupはアプリケーションが任意に指定することができ、その管理はKafka Brokerにて稼働するConsumer Group Coordinatorというプロセスが行います。Consumer Group CoordinatorはGroupメンバーの追加/削除の自動検知とリバランスを担当し、Consumer Groupメンバーの追加/離脱やこれらの死活監視、グループメンバーシップをトリガーとした処理のリバランス (メンバーへのPartitionのリアサイン) を自動的に行います。Consumer Groupの仕組みは、ストリームアプリケーションの可用性と拡張性に重要な役割を担っています。
一方、メッセージ処理の順序保証を前提としている為、 Partitionに複数のConsumerを設定する事が出来ず、この為Topicに指定するPartition数が並列処理能力の拡張性を決定します。 また、そもそも順序性の保証が不要なユースケースであってもConsumer Groupのルールに則らないといけないという制約は存在します。大容量のデータ処理 and/or 非常に柔軟な拡張性の制御が要求されるようなユースケースでは課題となり得る、というより歯痒い条件と見られる事もあります。
これまでのアプローチ
ほとんどのユースケースでは6、10、12といったベストプラクティスに沿ったPartition数を指定する事により、充分な並列処理能力と拡張性を確保することが出来ます。仮にどれだけの並列処理能力が求められるとしても、将来的にも1処理に対して24インスタンスによる並列処理が必要となる事が無いのであれば、Partition数を24としておけば安全圏です。一般的にはこのアプローチが多く取られます。
LINE Decaton はLINE Corporationが社内利用の為に開発しオープンソース化したKafkaライブラリです。大容量のストリーム処理を安定的に、かつKey単位の順序保証とAt Least Onceのデリバリを保証する事が可能です。
Confluent Parallel Consumer はConfluentがオープンソースで提供している分散処理Kafkaライブラリです。こちらもKey単位での順序保証をしており、順序保証しない設定を含め柔軟に処理構成を変更することが出来ます。
Queue for Kafka - Kafka Nativeなアプローチ
Queues for KafkaはConsumer Groupと異なる新しいグループ化を提供するものです。Share Groupと呼ばれ、Partition数に影響なくメンバーを追加することが出来ます。
Shared Groupは全く異なるインターフェースではなく、これまでのConsumer Groupと同列に扱われ、group.typeをshare1と設定する事によって指定します。Consumer Groupの場合、Partition数を超えるメンバーを指定しても処理に参加できなかったり、Partition数をきっちり割り切れるメンバー数でないとアサインメントに偏りが出ますが、Share Groupの場合は任意のメンバー数を指定する事により均一かつ水平にスケールします。
Consumer Groupと構成も同じで、BrokerのうちConsumer Group CoorinatorではなくShare Group Coordinatorを司るプロセスがグループメンバーの死活監視、リバランス等をConsumer Group同様に実施します。アプリケーション観点でもデプロイ観点でも、Consuemr Groupとの差はなく、あくまでプロパティ設定するのみでグループの振る舞いを変えることができます。
おわりに
Kafkaというはそのシンプルな設計ゆえに、十分理解しないと活用が難しいイメージがありました。ただこのシンプルさによってスケーラビリティとあらゆるユースケースでの活用することができ、Kafkaの理解を深める事はより良い設計をする上で非常に重要です。KIP-932は、Kafka誕生から変わることの無かったConsumer Groupというアプローチとは異なるデータアクセスのパターンに対する変更という意味では非常に興味深いKIPです。
group.typeは新しいプロパティ。デフォルトはconsumerであり、この指定だと通常通りConsumer Groupとして機能する。デフォルトはconsumerである為下位互換性あり。 ↩︎