Kafkaの利用が適さないユースケースとは?

このブログエントリはConfluent Field CTOであるKai Waeehnerのサイトで2022/1/4に公開された When NOT to use Apache Kafka?の日本語訳です。Kai本人の了承を得て翻訳/公開しています。
Apache Kafkaは、Data in Motionにおけるイベントストリーミングのデファクトスタンダードです。あらゆる業界でその採用が大きく伸びているため、私は毎週のように『ではApache Kafkaを使うべきでは無いのはどんな場合?』『ストリーム処理の基盤に重要な要素は?』『kafkaにこの機能性が無いのはなぜ?』『Kafkaを採用しないと判断する為の条件とは?』という質問を受けます。このブログ記事では、Kafkaを使うべき時、Kafkaを使うべきでない時、そしてKafkaを使うべきかもしれない時について順番に説明します。
市場動向 - コネクテッド・ワールド
まずは、なぜKafkaがいたるところで登場するのかを理解することから始めます。このことは、イベントストリーミングに対する市場の大きな需要を明らかにすると同時に、すべての問題を解決する銀の弾丸は存在しないことを示しています。Kafkaは繋がる世界 (コネクテッドワールド) の特効薬ではなく、重要なコンポーネントと捉える必要があります。
世界はますます繋がりを広げています。膨大な量のデータが生成され、収益増加、コスト削減、リスク軽減のためにリアルタイムに関連付ける必要があります。この動きはどの業界でも進んでいますが、より速い業界もあれば遅い業界もあります。しかしこの繋がりはあらゆるところに届いています。製造業、スマートシティ、ゲーム 、小売、銀行、保険などどこでもです。私の過去のブログには、どの業界にも関連するKafkaの使用事例を見つけることができます。
私はこのデータの急激な成長を、イノベーションと新しい最先端のユースケースの創出を示す2つのマーケットトレンドとして捉えています。(そしてKafkaの採用が業界を超えて急激である理由も併せて) 。
コネクテッド・カー - 膨大な量のテレメトリデータとアフターセールス
アライドマーケットリサーチの世界の機会分析と産業予測、2020-2027年 からの引用です:
ゲーミング - 数十億人のプレーヤーと巨額の収益
ゲーム産業はすでに他のすべてのメディア・カテゴリーを合わせたよりも大きくなっており、Bitkraftが描くように、これはまだ新しい時代の始まりに過ぎないとも言えます。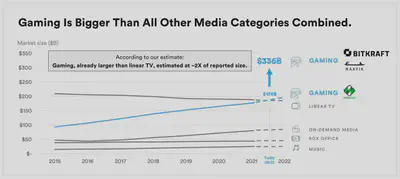
既に世界中で毎月何百万人もの新規プレイヤーがゲームコミュニティに参加しています。インターネットへの接続性と安価なスマートフォンは、それほど裕福でない国でも広く普及しています。 Play to Earnのような新しいビジネスモデルは、次世代のゲーマーのゲームの遊び方を変えており、5Gのような拡張性の高い低遅延技術が新たなユースケースを可能にしています。更にはブロックチェーンとNFT(Non-Fungible Token)は、マネタイズとコレクター市場を永遠に変えようとしています。
業界を横断するこうした市場動向は、リアルタイムデータ処理のニーズが四半期ごとに大幅に増加している理由を明らかにしています。Apache Kafkaは分析およびトランザクションデータ ストリームを大規模に処理するためのデファクトスタンダードとしての地位を既に確立しています。しかしながら、Apache Kafkaとその周辺エコシステムの技術をプロジェクトで使用する(しない)タイミングを理解することも併せて非常に重要です。
Apache Kafkaとは何で、何では無いのか?
Kafkaは誤解されやすい技術です。例えばKafkaはメッセージキューだという話をいまだによく耳にします。その理由のひとつは、一部のベンダーが自社製品を売るために特定の問題(データレイクやデータウェアハウスへのデータ取り込みなど)に対してのみKafkaを売り込んでいるからだと思われます。
Kafkaは:
- スケーラブルなリアルタイム・メッセージング・プラットフォームで、毎秒数百万のメッセージを処理する。
- 大量のビッグデータ分析から少量のトランザクションデータ処理まで対応するイベント・ストリーミング・プラットフォーム。
- 分散ストレージは、背圧処理のための真のデカップリングを提供し、様々な通信プロトコルをサポートし、順序が保証されたイベントの再生可能性を提供する。
- ストリーミングETLのためのデータ統合フレームワーク。
- ステートレスまたはステートフルな連続ストリーム処理のためのデータ処理フレームワーク。
これら様々なユースケース/利用パターンを一つのプラットフォームで提供出来る点がKafkaの特徴です。
一方以下はKafkaに当てはまりません:
- 数百万を超えるクライアントからの直接接続 - Kafkaネイティブのプロキシ(RESTやMQTTなど)、いくつかのユースケースに対応しているが全てではない。
- API管理プラットフォーム - これらのツールは通常補完的であり、Kafka APIの作成、ライフサイクル管理、または収益化のために使用される。
- バッチ分析や複雑なクエリをサポートするDB - トランザクションクエリや比較的単純な集計(特にksqlDBを使用)では充分扱える。
- デバイス管理を行うIoTプラットフォーム - MQTTやOPC-UAなどのIoTプロトコルとKafkaを直接統合することは可能であり、(一部の)ユースケースには適切なアプローチである。
- ミリ秒レイテンシを達成するハード・リアルタイム・アプリケーションのための技術 (セーフティ・クリティカル・システムや決定論的システム) - ただ組み込みソフトウェアを除くと全てのプラットフォームが同様であり、Kafkaもその例外では無いというだけである。
このような理由から、Kafkaは他のテクノロジーと競合するものではなく、補完するものであると言えます。仕事に適したツールを選び、それらを組み合わせる上でKafkaは全体における重要な要素となり得ます。
コネクテッドワールドにおけるApache Kafkaのケーススタディ
ここではKafkaを他のテクノロジーと組み合わせることで、ビジネス上の問題を解決した素晴らしいサクセスストーリーの例をいくつか紹介します。エンドツーエンドのデータフローにKafka以上のものを必要とするケーススタディに焦点を当てています。
私のブログ、Kafka Summitカンファレンス、MediumやDzoneのようなオンラインリソース、その他の技術関連のニュースなど、どれをフォローしても同じです。コネクテッドカー、IoTエッジデバイス、スマートフォンのゲーム/アプリなどからの大量のアナリティクスやトランザクショ・データをApache Kafkaでリアルタイム データストリー ミングする成功例をたくさん見つけることができます。
業種や使用例をいくつか挙げてみます:
- AUDI - コネクテッドカー・プラットフォームが地域とクラウドプロバイダーを横断的に展開。
- BMW - サプライチェーンとロジスティクスの最適化を実現するスマート工場。
- SolarPower - 太陽光発電のソリューションとサービスを世界中で提供。
- Royal Caribbian - エッジサービスとハイブリッド・クラウドの集約によるクルーズ船のエンターテイメント。
- Disney+ Hotstar - インタラクティブなメディアコンテンツとゲーム/ベッティングをスマートフォンで数百万人のファンに提供。
このような素晴らしいIoTのサクセスストーリーにおいてKafkaは課題はあるかというと、問題無く非常に有機的に機能しています。しかしながら、Apache Kafkaエコシステムでイベントストリーミングを使用するタイミングと、他の補完的なソリューションを利用すべきかの判断について説明するためには、いくつか明確化が必要です。
Apache Kafkaを使うべき場合
Kafkaを使うべきでない場合について説明する前に、Kafkaを使うべき場所を理解し、必要に応じて他のテクノロジーと補完する方法とタイミングをより明確に説明します。ここから実例をユースケースごとに分けていくつかご紹介します。
Kafkaは大量のIoTやモバイルデータをリアルタイムかつ大量に扱う事ができる。
Teslaは単なる自動車メーカーではありません。Teslaは、革新的で最先端のソフトウェ アを数多く開発しているハイテク企業です。Teslaは自動車のためのエネルギーインフラも併せて提供しています。スーパーチャージャー、ギガファクトリーでの太陽エネルギー生産等も然りです。
車両、スマートグリッド、工場からのデータを処理/分析し、残りのITバックエンドサービスとリアルタイムで統合することは、同社の成功に不可欠な要素です。
TeslaはKafkaベースのデータプラットフォームインフラを構築し『1日あたり数百万台のデバイスと数兆のデータポイントをサポート』しています。テスラは2019年のKafka Summitで、彼らのKafka利用のな歴史とその進化について登壇しています。
私はほとんどすべてのブログエントリでこのことを繰り返していますが、Kafkaは単なるメッセージングではないことを改めて強調させてください。Kafkaは分散ストレージレイヤーであり、プロデューサーとコンシューマーを真に分離し、さらにKafka StreamsやksqlDBのようなKafkaネイティブの処理ツールによってリアルタイム処理を可能にします。
KafkaはIoTデータとMESやERPシステムからのトランザクションデータを結び付ける
規模の大きなリアルタイムでのデータ統合には、アナリティクスやERPやMESシステムのようなトランザクションシステムの利用に密接に関連しています。Kafka Connectやその他非Kafkaミドルウェアは、このタスクのためにイベントストリーミングのコアを補完する役割を果たします。
BMWはエッジ(スマート工場など)とパブリッククラウドでミッションクリティカルなKafkaワークロードを運用しています。Kafkaはこれらシステムの疎結合性/透明性を高め活用によるイノベーションを可能にします。併せてConfluentの製品と専門知識により安定性を担保しています。後者は製造業での成功に不可欠です - 1分のダウンタイムによって組織に莫大なコストがかかリマス。関連記事Apache Kafka as Data Historian - an IIoT / Industry 4.0 Real-Time Data Lakeをご参照ください。Kafkaが製造業の総合設備効率(OEE)をどのように改善出来るか理解頂けると思います。
BMWはリアルタイムでサプライチェーン管理を最適化しています。このソリューションは、物理的にもBMWのERP(SAP搭載)のようなトランザクションシステムにおいても、 適切な在庫に関する情報を提供します。「Just-in-Time/Just-in-Sequence」は、多くのアプリケーションにとって極めて重要です。KafkaとSAPの統合は、この分野で私が話をする顧客のほぼ半分で必要とされています。また、統合だけでなく多くの次世代トランザクションERPやMESプラットフォームもKafkaを利用しています。
Kafkaはエッジやハイブリッド/マルチクラウドにおいて、企業内のすべての非IoT ITと統合する
Apache Kafkaのマルチクラスタおよびデータセンター間のデプロイは例外ではなく、むしろ一般的なアプローチになりつつあります。マルチクラスタが必要となる可能性のあるいくつかのシナリオについて学び、DR、分析のための集約、クラウドへのマイグレーション、ミッションクリティカルな拡張クラスタの展開、global Kafkaなど、具体的な要件とトレードオフの実例をご確認ください。
異なるインターフェース間の真の疎結合化は、IBM MQやRabbitMQ、MQTTブローカーなどの他のメッセージング・プラットフォームに対するKafkaの競争優位です。この点については、Kafkaを使ったドメイン駆動設計(DDD)についての記事でも詳しく説明しました。Apache Kafkaを使用したインフラの近代化とハイブリッドクラウドアーキテクチャは、業界を問わず一般的です。
私が好きな例のひとつにUnityの成功例があります。同社はゲームに特化したリアルタイム3D開発プラットフォームで、拡張現実(AR)/仮想現実(VR)機能により製造業など他の産業にも進出しています。
データ主導型の同社は、2019年にすでにコンテンツが330億回インストールされ、世界中の30億台のデバイスに届いています。併せてUnityは世界最大級のマネタイズネットワークを運営しています。彼らはこのプラットフォームを自己管理のオープンソースKafkaからフルマネージドのConfluent Cloudに移行しました。カットオーバーはダウンタイムやデータ損失なしにUnityのプロジェクトチームによって実施されました。Unityの取り組みはConfluentブログUsing Confluent Platform to Complete a Massive Cloud Provider Migration and Handle Half a Million Events Per Secondでご紹介しています。
Kafkaはモビリティサービスやゲーム/ベッティングプラットフォーム向けのスケーラブルなリアルタイムバックエンドである
多くのゲームやモビリティサービスは、インフラのバックボーンとしてイベントストリーミングを活用しています。ユースケースには、遠隔測定データの処理、位置情報サービス、決済、不正検出、ユーザー/プレイヤーの維持、ロイヤリティプラットフォームなど、多くのものが含まれます。この分野のほとんどすべての革新的なアプリケーションは、スケールの大きなリアルタイム データストリーミングを必要とします。
いくつか例を挙げます:
- モビリティサービス - Uber、Lyft、FREE NOW、Grab、Otonomo、Here Technologies 、etc.
- ゲームサービス - Disney+ Hotstar、Sony Playstation、Tencent、Big Fish Games、etc.
- ベッティングサービス - William Hill、Sky Betting、etc.
これらユーザーが常に公の場でKafkaの使用について話しているわけではありません。しかしモビリティサービスやゲームサービスの求人ポータルを見れば分かりますが、ほとんどの企業がプラットフォームを開発/運用するKafkaのエキスパートを常に探しています。
これらのユースケースは、コア・バンキング・プラットフォームにおける決済プロセスと同様に重要です - 規制やコンプライアンス、データ損失ゼロという保全要件が同様に当てはまります。Multi Region Cluster(MRC - 米国東部、中部、西部のような地域にまたがるKafkaクラスタ)は、ダウンタイムゼロの高可用性を実現し、災害の場合でもデータ損失はありません。
車両、マシン、IoTデバイスに単一のKafkaブローカーを組み込む
エッジにおけるKafkaの利用は一定数の成功を収め、また今後も成長します。一部のユースケースでは、データセンター外にKafkaクラスタまたはシングルブローカーを展開する必要があります。Kafkaインフラをエッジで運用する理由には、低レイテンシー、コスト効率、サイバーセキュリティ、インターネット接続がないことなどがあります。
エッジKafka特有の用件としては:
- Disconnected edge - 物流センターで良好なインターネット接続が利用できるようになるまで、ログ/センサーデータ/画像をオフラインの状態(例えば、路上のトラックや船の周りを飛行するドローン)で保全する。
- 小規模なローカルデータセンターにおけるVehicle-to-Everything (V2X) コミュニケーション - AWS Outpostsのようなエリアが広い、車両数が多い、ネットワークが貧弱な場合はMQTTのようなゲートウェイを経由し通信する。またはスマートファクトリーなど数百台のマシンの場合はKafkaクライアントとの直接接続を経由して通信する。
- Offline mobility services - 自動車インフラとゲーム、地図、ある いはレコメンデーション・エンジンとローカルに処理されたパートナーサービス(例えば『あと10マイルでマクドナルドが届きます』『クーポンはこちらです 』)を統合する。
Royal Caribbeanクルーズラインは、このシナリオの偉大な成功例です。世界で4番目に大きな客船を運航しています。2021年1月現在同社は24隻の客船を運航しており、さらに6隻の客船を発注中です。
Royal Caribbeanは、Kafkaの最も有名なユースケースの1つをエッジで実装しています。各クルーズ船は、決済処理、ロイヤルティ情報、顧客推奨などのユースケースのために、ローカル(つまり船上)で Kafkaクラスタを運用しています: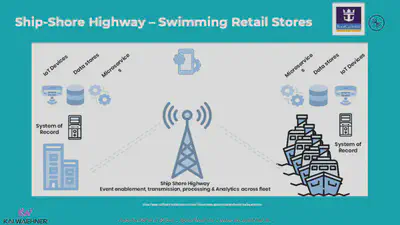
私はこの事例や他のKafkaエッジ展開を様々なブログで取り上げました。エッジでのKafkaのユースケースについて話したり、エッジでのKafkaのアーキテクチャを紹介したり、 Kafkaを利用した低遅延の5Gデプロイメントについても説明しています。
Apache Kafkaを使うべきでない場合
ようやく主題の話となりますが、まずKafkaを使うアプローチについて理解する事が重要なのでご説明しました。では、Kafkaを使うべきでない場合はその逆なので比較的簡単です。
このセクションでは、コンセプトの実証のための非現実的な構成ではなく本番利用を前提とします。検証の場合取り急ぎの構成で確認することはありますが、インフラをグロ ーバルに拡張し、コンプライアンスに準拠し、かつデータ欠損を許容しない保証をする場合には妥当ではありません。あくまで本番利用の観点で見る事により、比較的容易にKafkaの採択が妥当ではないという評価も可能です。
Kafkaはハードリアルタイムではない
『リアルタイム』という言葉の定義は難しく、マーケティング用語であることが多くあります。実際にリアルタイムシステムは、指定された時間の制約の中で応答を保証しなければならない、という条件を満たしたものとなります。
Kafkaに限らず、同じ文脈で使用されるその他のフレームワーク、製品、クラウドサービスはすべてソフト・リアルタイムのみです。OTやIoTの世界では、レイテンシのスパイクが全くないハードリアルタイムを必要とする場合も多くあります。
一方ソフトリアルタイムのユースケースは:
- ITアプリケーション間のP2Pのメッセージング
- さまざまなデータソースから1つまたは複数のデータシンクへのデータ連携
- データ処理とデータ連携(しばしばイベントストリーム処理と呼ばれるもの)
であり、ミリ秒以下のレイテンシーを必要とするアプリケーションの場合、Kafkaは適切な選択ではありません。例えば、リアルタイム決済取引は通常、専用の商用ソリューション上に実装されます。
この点は強調したいのですが、最もレイテンシーが低いのは、メッセージングシステムを一切使わず、共有メモリだけを使うアプローチです。極限まで低レイテンシを求める場合にはKafkaは向きません。一方、監査ログやトランザクションログ、それらの永続化やデータ整合性の担保等が必要な場合にはKafkaは非常に有効な選択肢です。
リアルタイムのユースケースのほとんどは、ミリ秒から秒単位のデータ処理が必要要件であり、その場合Kafkaは適切なソリューションです。Robinhoodのような多くのFinTech企業は、ミッションクリティカルなトランザクション、さらには金融取引に至るまでKafkaに依存しています。マルチアクセス・エッジコンピューティング(MEC)は、Kafkaとクラウドネイティブな5Gインフラによる低遅延データストリーミングのもう一つの優れた例です。
Kafkaは組込みシステムや安全関連システムには不向き
これは前項との補足的な意味合いで、Kafkaは瞬時な対応が必要不可欠な場合には利用すべきではありません。例えば、自動車のエンジン制御システム、 心臓ペースメーカーなどの医療システム、産業用ロボットの異常検知等、全く遅延なくかつ確実に対応が求められるユースケースがそれに該当します。
これらユースケースの例では:
- 自動車や車両における安全関連データ処理 - これらはAutosar/MINRA C/アセンブラ等のソリューションが適切です。
- ECU間のCAN Bus通信
- ロボット工学 - C/C++または類似の低レベル言語と、産業用ROS(ロ ボット・オペレーティング・システム)などのフレームワークを組み合わせたソリューションが適切です。
- 安全関連の機械学習/ディープラーニング(自律走行用など)
- 車両間(V2V)通信 - Kafkaのような仲介者を介さない5G sidelinkの方が適切です。
などが挙げられますが、別途Apache Kafka is NOT Hard Real Time BUT Used Everywhere in Automotive and Industrial IoTにてより詳細に説明しています。
TL;DR: 安全関連のデータ処理は、専用の低レベルプログラミング言語とソリューションで実装する必要があります。それはKafkaではなく、また他のITソフトウェアにも同じことが言えます。したがって、KafkaをIBM MQ、Flink、Spark、Snowflake、その他類似のITソフトウェアに置き換えても解決しません。
不安定なネットワーク上での接続に不向き
Kafkaは、KafkaクライアントとKafkaブローカー間の安定したネットワーク接続を必要とします。したがって、ネットワークが不安定でクライアントが常にブローカーに再接続する必要がある場合、運用は困難となり、高SLAを達成するのは難しくなります。
例外もありますが、基本的な経験則として他のテクノロジーは不安定なネットワークの問題を解決するために特別に設計されています。例えばMQTTが最も顕著な例です。KafkaとMQTTは敵同士ではなく、組み合わせる事によって相互の欠点を補う事ができると考えるべきです。この組み合わせは非常に強力で、業界を問わず多く使われています。この組み合わせは別のブログシリーズとして残しています。
何万ものクライアントからの直接接続には不向き
統合ソリューションとしてKafkaを除外するもう1つの具体的なポイントは、Kafkaは何万ものクライアントに接続できないという点です。コネクテッドカーのインフラやモバイルプレーヤー向けのゲームプラットフォームを構築する必要がある場合、クライアント (車やスマートフォンなど) をKafkaに直接接続することは得策ではありません。
この場合、HTTPゲートウェイやMQTTブローカーのような専用プロキシとの併用が有効です。リアルタイムのバックエンド処理や、データレイク/データウェアハウス/リアルタイムアプリケーションの様なデータシンクとの統合のために、何万ものクライアントとKafkaの間の適切な仲介役として機能します。
『ではKafkaクライアント接続数の限界はどのくらいか?』と聞かれますが、これはよくあることですが『ケースバイケースです』としか答えようがありません。.NETやJavaのKafkaクライアントを経由して、工場の現場からKafkaクラスタが稼働しているクラウドに直接接続している顧客を見たことはあります。マシン/PLC/IoTゲートウェイ/IoTデバイスの数が数百台であれば、ハイブリッドの直接接続は比較的上手くいきます。クライアント/アプリケーションの数がこれより多い場合は、a) 中間にプロキシが必要か、b) 低レイテンシでコスト効率の高いワークロードを実現するために、エッジにKafkaを使うか、選択肢はあります。後者はエッジコンピューティングにもKafkaを導入するかどうかを評価する必要が合わせてあります。
ケースバイケースでApache Kakfaが使える場合
これまではKafkaの機能や仕組み上比較的簡単にKafkaがフィットしないユースケースについて説明しました。今度はケースバイケースで採用が可能、評価にはその他複数の検討要件があるユースケースを取り上げます。
Kafkaは(一般的な)データベースの置き換えにはならない
ある意味Kafkaはデータベースです。ACID保証を提供し、何百もの企業でミッションクリティカルなワークロードに使用されています。しかし、ほとんどの場合Kafkaは他のデータベースと競合しません。Kafkaは、メッセージング、ストレージ、処理、統合を、ダウンタイムやデータ損失ゼロでリアルタイムに大規模に行うためのイベント・ストリーミング・プラットフォームです。
Kafkaはこのような特徴を持つストリーミング統合レイヤーの中心として使用される事が多いです。その他のデータベースはその周辺には存在し、リアルタイムの時系列分析、テキスト検索インフラへのリアルタイムの取り込み、データレイクへの長期保存など、特定のユースケースのためにデータをマテリアライズする役割で使用できます。
『Kafkaをデータベースの代替として利用できるか?』を考える場合:
- Kafkaは、ACID保証を提供する耐久性と可用性の高い方法でデータを恒久的に保存することができる。
- Kafkaには履歴データを照会するためのさらなるオプションを提供する。
- ksqlDBやTiered StorageのようなKafkaネイティブなアドオンにより、Kafkaはデータ処理やイベントの長期保存にさらに選択肢が増える。
- Kafkaクライアント (マイクロサービス、業務アプリ) を活用することで、他の外部データベースなしでステートフルなアプリケーションを構築できる。
- MySQL、MongoDB、Elasticsearch、Hadoop、Snowflake、Google BigQueryなど、既存のデータベース、データウェアハウス、データレイクを置き換えるものではない。
- 他のデータベースとKafkaは互いに補完し合う。課題に応じて適切なソリューションを選択する必要がある。多くの場合、専用のマテリアライズド・ビューとしてデータベースが利用され、中央のイベントベース・インフラからリアルタイムで更新される。
- Kafkaとデータベース間の双方向のプルおよびプッシュベースの統合には、さまざまなオプションが用意されておりお互いを補完することができます。
といった観点から評価する必要があります。Can Apache Kafka Replace a Database?ではこのKafkaをデータベースとして利用する場合の考慮点についてさらに深く言及しています。
Apache Kafkaは(一般的に)サイズの大きなメッセージの処理に向かない
Kafkaは大きなサイズのメッセージを扱う様に設計されていません。
それにもかかわらず、Kafka経由で1Mb、10Mb、さらにはもっと大きなファイルやその他の大きなペイロードを送信し処理するプロジェクトが増えています。その理由の1つは、Kafka が大容量/スループット向けに設計されており、その特性が大容量メッセージの転送にとって重要だからです。よくある例としては、レガシーシステムからKafkaを使って大きなファイルを取り込み、処理したデータをデータウェアハウスに取り込むというものがあります。
しかし、すべての大きなメッセージをKafkaで処理する必要性はありません。多くの場合、適切な別のストレージシステムを使い、オーケストレーションにだけKafkaを活用すべきです。参照ベースの同期(つまりファイルを別のストレージシステムに保存し、リンクとメタデータを送信する)の方が良いデザインパターンであることが多いです。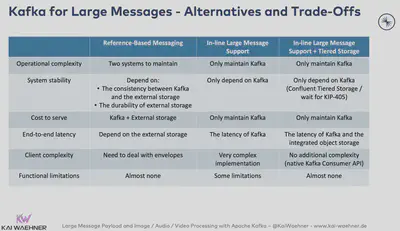
いくつかある選択肢のうち、特定の課題に対して適切なソリューションを選択する必要があります。詳しくはHandling Large Messages with Apache Kafka (CSV, XML, Image, Video, Audio, Files)で詳しく説明しています。
Kafkaは(一般的に)産業用プロトコルのIoTゲートウェイではない
IoTインターフェースやモバイルアプリへのエンドポイントの提供はなかなかに難しい課題です。上述したように、Kafkaは何万ものKafkaクライアントに接続することはできません。しかし多くのIoTやモバイルアプリでは、数十から数百の接続しか必要としません。その場合Kafkaネイティブ接続は (地球上のほぼすべてのプログラミング言語で利用可能な) さまざまなKafkaクライアントのいずれかを使用して簡単にできます。
KafkaクライアントとのTCPレベルでの接続が現実的ではないとします。このような場合、クライアントとKafkaクラスタの仲介役としてRESTプロキシを利用するのが一般的です。クライアントは、ストリーミングプラットフォームと同期HTTP(S) を介して通信します。
Apache Kafkaを使ったHTTPとREST APIのユースケースにて言及していますが、Control Plane(=管理)、Data Plane(=メッセージの生成と消費)、自動化(それぞれDevOpsタスク)を含みます。
ただ実際には、多くのIoTプロジェクトではもっと複雑な統合が必要となります。MQTTやOPC-UAコネクターを介した比較的簡単な統合だけではなく、産業用IoTプロジェクトではさらに以下のような課題があります:
- オートメーション業界はオープンスタンダードを使用していないことが多いが、遅 く、安全でなく、拡張性がなく、プロプライエタリである。
- 製品のライフサイクルは非常に長く(数十年)、簡単な変更やアップグレードはできな い。
- IIoT(Industrial IoT)は通常、互換性のないプロトコルを使用しており、通常は特定のベンダーによって独自に構築されている。
- 原則拡張性の無い、独自で高価なモノリシックコンポーネントで構成されている。
多くのIoTプロジェクトでは専用のIoTプラットフォームでKafkaを補完するアプローチを取っています。ほとんどのIoT製品やクラウドサービスはプロプライエタリですが、オープンなインターフェースとアーキテクチャも存在します。この業界ではオープンソースの領域は大きくありません。ただ一部のユースケースではApache PLC4Xが素晴らしい選択肢となり得ます。このフレームワークはSiemens S7、Modbus、Allen Bradley、Beckhoff ADSといった多くのプロプライエタリなレガシープロトコルとの統合を可能にします。合わせてPLC4Xはネイティブでスケーラブルな Kafka統合用のKafka Connectコネクタも提供しています。
モダンなデータヒストリアンのアプローチはオープンかつ柔軟になり得ます。工場ラインとハイブリッドクラウドを繋ぐ様な戦略的IoTプロジェクトの基盤は、イベントストリーミングによって支えられています。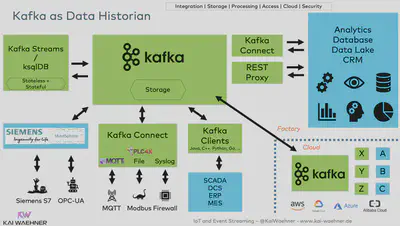
Kafkaはブロックチェーンではない(ただし、web3、暗号取引、NFT、オフチェーン、サイドチェーン、オラクルには関係する)
Kafkaは仕組みとしては『分散コミットログ』です。またその概念と基盤はブロックチェーンと非常ににています。これについてはApache Kafka and Blockchain – Comparison and a Kafka-native Implementationという投稿で詳しく説明しました。
ブロックチェーンは、お互いが信頼できない関係者が協力する必要がある場合にのみ使うべき技術です。ほとんどの企業プロジェクトにとって、ブロックチェーンは不必要な複雑さを追加する事にもなります。分散コミットログ(=Kafka)か、改ざん防止の分散台帳(=拡張Kafka)で充分なケースがほとんどです。
さらに興味深いことに、暗号取引プラットフォーム、市場取引所、NFTトークン取引マーケ ットプレイスでKafkaを使用する企業が増えています。
ここで改めて、Kafkaはこれらのプラットフォームにおけるブロックチェーンとして機能している訳ではないという点を強調しておきます。ブロックチェーンとは、ビットコインのような暗号通貨や、イーサリアムのようなスマートコントラクトを提供するプラットフォームのことで、人々はゲームやアート業界のNFTのような新しい分散アプリケーション(dApps)をその上に構築します。一方Kafkaは、これらのブロックチェーンをCRM、データレイク、データウェア ハウスなどの他のオラクル(=非ブロックチェーンアプリ)と接続するためのストリーミングプラットフォームとして機能します。
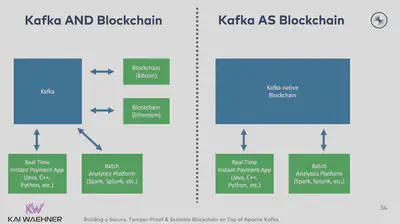
TokenAnalystは、ビットコインとイーサリアムからのブロックチェーンデータを分析ツールと統合するためにKafkaを活用している優れた例です。Kafka Streamsはステートフル・ストリーミング・アプリケーションを提供し、ダウンストリームの集計計算で無効なブロックの使用を防ぎます。例えばTokenAnalystはブロックを一時的に保持することで再編成シナリオを解決し、確認数(そのブロックの子ブロックが採掘される)の閾値に達した場合にのみ伝播する『ブロック・コンファイラー・コンポーネント』を開発しました。
一部の高度なユースケースでは、オリジナルのブロックチェーンが十分にスケールしない為、サイドチェーンまたはオフチェーンプラットフォームの実装にKafkaが使用されています (ブロックチェーンはオンチェーンデータとして認識)。ビットコインに限らず、1秒間に1桁(!)のトランザクションしか処理できないというスケーラビリティの課題があります。 最新のブロックチェーン・ソリューションのほとんどは、Kafkaがリアルタイムで処理する拡張性に遠く及びません。
DAO (分散型自律組織) から優良企業に至るまで、ブロックチェーンインフラとIoTコンポーネントの健全性を測定することは分散型ネットワークであっても必要です - ダウンタイムを回避し、インフラを保護し、ブロックチェーンデータにアクセスできるように配慮する必要があります。Kafkaはスケーラブルなデータの供給基盤として、ノードが失われる前に確実に関連システムに伝達する役割を果たします。これはHelium のような最先端のWeb3 IoTプロジェクトや、R3 Cordaのようなシンプルなクローズド分散型台帳(DLT)に関連しています。
イベントストリーミングとKafkaを活用したライブコマースが小売業のメタバースを変革するという私の最近の投稿では、小売業とゲーム産業がいかに仮想的なものと物理的なものを結びつけているかの良い事例です。小売業のビジネスプロセスと顧客とのコミュニケーションはリアルタイムで行われ、洋服、スマートフォン、あるいはブロックチェーンベースのNFTトークンを使ったコレクターズアイテムやビデオゲームの販売等々に業界の差なく広く行われています。
TL;DR: Kafkaとは…
- 現行データベースやデータウェアハウスの代替となる。
- 安全関連システムや組込みワークロードのためのハードリアルタイムを提供
- 不安定なネットワークを経由した何万ものクライアントとの接続
- API管理ソリューション
- IoTゲートウェイ
- ブロックチェーン
これらユースケースにはKafkaは不向きであり、比較的容易に選択肢から外すことはできます。
しかし、あらゆる業界の分析ワークロードやトランザクションワークロードがKafkaを使用しています。Kafkaはイベントストリーミングのデファクトスタンダードです。それゆえ、Kafkaはしばしば他のテクノロジーやプラットフォームと組み合わせる事が前提となります。